课堂课题:
什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
关联任务:
任务五
直播时间:
2018-12-28 15:30:00
课堂内容:
视频链接:
PPT链接:
提交按钮:
小课堂内容格式
标题:
【修真院xx(职业)小课堂】课题名称
开场语:
大家好,我是IT修真院XX分院第X期的学员XX,一枚正直纯洁善良的XX程序员,今天给大家分享一下,修真院官网XX(职业)任务X,深度思考中的知识点——XXX
(1)背景介绍:
背景介绍的时候,尽可能的要宽广,讲清楚来龙去脉,讲清楚为什么会需要这个技术。
(2)知识剖析:
讲知识点的时候,尽可能的成体系,学会成体系的去给别人介绍知识。现在很多做的都是零散的,没有分类。
(3)常见问题:
最少列出1个常见问题。
(4)解决方案:
写清楚常见问题的解决方案。
(5)编码实战:
尽可能的去寻找在真实项目中在用的。如果你能找到某个网站在用你说的知识点,这是最好的。学以致用,否则当成练习题就没有意义了。多准备一些demo,讲解过程中将知识点和demo结合,便于大家理解所讲解的知识点。
(6)拓展思考:
知识点之外的拓展思考,由分享人进行讲解,这些东西就是所谓的深度,也是一个人技术水准高低比较的表现。
(7)参考文献:
引入参加文献的时候,在引用的句子后面加上序号【1】。参考文献中列出详细来源。不要去抄别人的东西,这是一个基本的态度。
(8)更多讨论:
Q1:提问人:问题?
A1:回答人(可以是分享人,也可以是其他学员):回答
Q2:提问人:问题?
A2:回答人(可以是分享人,也可以是其他学员):回答
Q3:提问人:问题?
A3:回答人(可以是分享人,也可以是其他学员):回答
(9)鸣谢:
感谢XX、XX师兄,此教程是在他们之前技术分享的基础上完善而成。
(10)结束语:
今天的分享就到这里啦,欢迎大家点赞、转发、留言、拍砖~
【修真院Java小课堂】什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
大家好,我是IT修真院北京分院第35期的学员,一枚正直纯洁善良的Java程序员,今天给大家分享一下,修真院官网Java(职业)任务六,深度思考中的知识点——什么叫集群?缓存应该在什么情况下使用集群?有哪些实现集群的方案?
1. 背景介绍
在说分布式和集群之前先说一下单机结构,单机结构是我们之前最常用的结构,所有代码都放在一个项目中,然后这个项目部署在一台服务器上,整个项目的所有服务都由这台服务器提供,但是当业务增长到一定程度时只能垂直向上进行扩展,通过增加CPU、内存和磁盘等方式提高处理能力,但是这种扩展方式的成本越来越高,而且单机的处理能力存在瓶颈,当单机出现故障时整个系统都会处于崩溃状态,稳定性和可用性难以得到保障。
分布式和集群
简单来说,分布式是以缩短单个任务的执行时间来提高效率的,而集群则是通过提高单位时间内执行的任务数来提升效率。
当单机处理能力达到瓶颈时,将单机复制几份分别部署,这几台单机就构成了一个集群,每一个单机服务器都是这个集群中的一个节点,每个节点都提供相同的服务,集群结构的优点就是系统扩展非常容易,随着业务的发展给集群增加节点就可以了,但是当业务发展到一定程度时增加集群节点对系统性能的提升会不明显。
分布式结构就是将一个完整的系统按照业务功能拆分成一个个独立的子系统,在分布式结构中,每一个子系统被称为服务,这些子系统能够独立运行在Web容器中,再以某种协议进行通信,比如说RPC和Http。
2. 知识剖析
缓存使用集群主要是为了保证系统的高可用,除了可以分担一台服务器的压力外,当一个缓存服务器宕机,大量缓存失效会导致缓存雪崩,大量请求涌向数据库,数据库瞬时压力过重。这是时用缓存会把宕机的主节点下的从节点上升为主节点,这也是从一方面来保证系统的高可用。
这里介绍一下常见的几种集群方案
客户端分区方案
客户端就已经决定数据会被存储到哪个节点或者从哪个节点读取数据,其主要思想是采用哈希算法将Redis数据的key进行散列,通过hash函数将key映射到节点上
这种做法的优点是不需要使用中间件,可自行控制分区逻辑。
缺点也很明显,无法动态进行服务节点的增删,需要手动进行维护。
代理分区方案
客户端将请求发送到代理组件,代理组件解析客户端的数据,并将请求转发至正确的节点。常见的中间件有Twemproxy 和Codis。
简化了客户端的逻辑,增删切换成本低
多了一层中间件,会导致一定程度上的性能损耗
查询路由方案
Redis Cluster 是redis自带的一种集群方案,客户端随机的请求任意一个Redis节点,然后由这个Redis节点将请求转发给正确的redis节点。
数据按照槽存储分布在多个Redis节点中,可以平滑进行增删节点,因为Redis Cluster是在Redis的主从模式和哨兵模式的基础上实现的,支持高可用和自动故障转移。
3.常见问题
4.解决方案
Redis Cluster
Redis-Cluster 是 Redis 官方的一个高可用解决方案,Cluster中的Redis共有2^14(16384)个slot槽。创建Cluster后,槽 会平均分配 到每个Redis节点上。
这是官方文档推荐的最基本的配置
port 7000
cluster-enabled
yes cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
集群中的节点会定时向其它节点发送请求,判断主观下线,然后投票判断是否客观下线,这个过程和哨兵的机制类似,所以有三个主节点的集群才是一个高可用的集群,这里配置一个三主三从一共六个节点的集群。
分别启动六个Redis节点,查看进程会发现这几个Redis运行在集群模式下

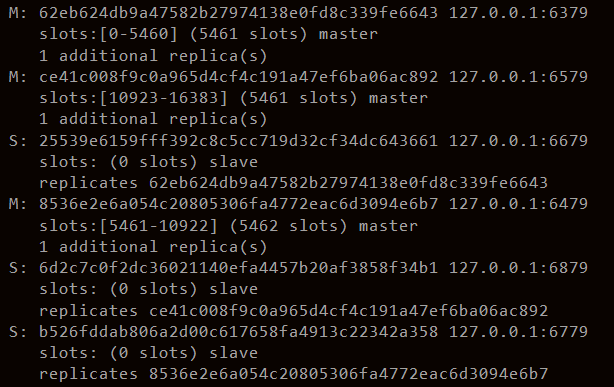
使用redis-cli --cluster create用这六个节点创建集群
会将slot槽分配到三个主节点上
数据会根据哈希值来分配到这三个节点上
5.编码实战
Spring整合RedisCluster
<bean id="jedisCluster" "org.springframework.data.redis.connection.RedisClusterConfiguration">
<property name="clusterNodes">
<set>
<bean "org.springframework.data.redis.connection.RedisNode"
c:host="${redis.hostName}"
c:port="${redis.cluster.port1}"/>
</set>
</property>
</bean>只要配置一个RedisCluster节点就够了,因为Cluster是通过节点来转发给正确的节点的,然后通过RedisTemplate操作数据就可以了。
6.扩展思考
7.参考文献
参考资料:https://juejin.im/post/5b8fc5536fb9a05d2d01fb11#heading-17
————深入剖析Redis系列(三) - Redis集群模式搭建与原理详解
8.更多讨论
RedisCluster是怎么解决哈希冲突的?
RedisCluster也是向HashMap一样通过链表法来解决哈希冲突的。
集群的数据分布一定要使用哈希算法吗?
使用哈希算法的目的是为了将数据均匀的分布到节点上,要是有其他的方法将每次访问的数据映射到同一个对应的节点上也是可以的。
为什用redis-trib.rb命令创建集群会失败
Redis新版本中已经把集群功能整合到redis-cli中了,之前的版本需要安装Ruby然后使用redis-trib.rb创建集群,新版本这个命令已经不能用了
9.鸣谢
感谢观看,如有出错,恳请指正
10.结束语
今天的分享就到这里啦,欢迎大家点赞、转发、留言、拍砖~
请您登录 后进行评论





[修真长老]JAVA-错遇 发表于 2019-01-04 09:35:52 #1
有一点点调研的意思了。 背景介绍应该介绍Hash,Redis的起源等。 知识剖析应该去讲Hash算法等。 常见问题应该是去讲在Redis Cluster之前这些方案存在的问题,然后才是去介绍Redis Cluster的解决方案。
回复